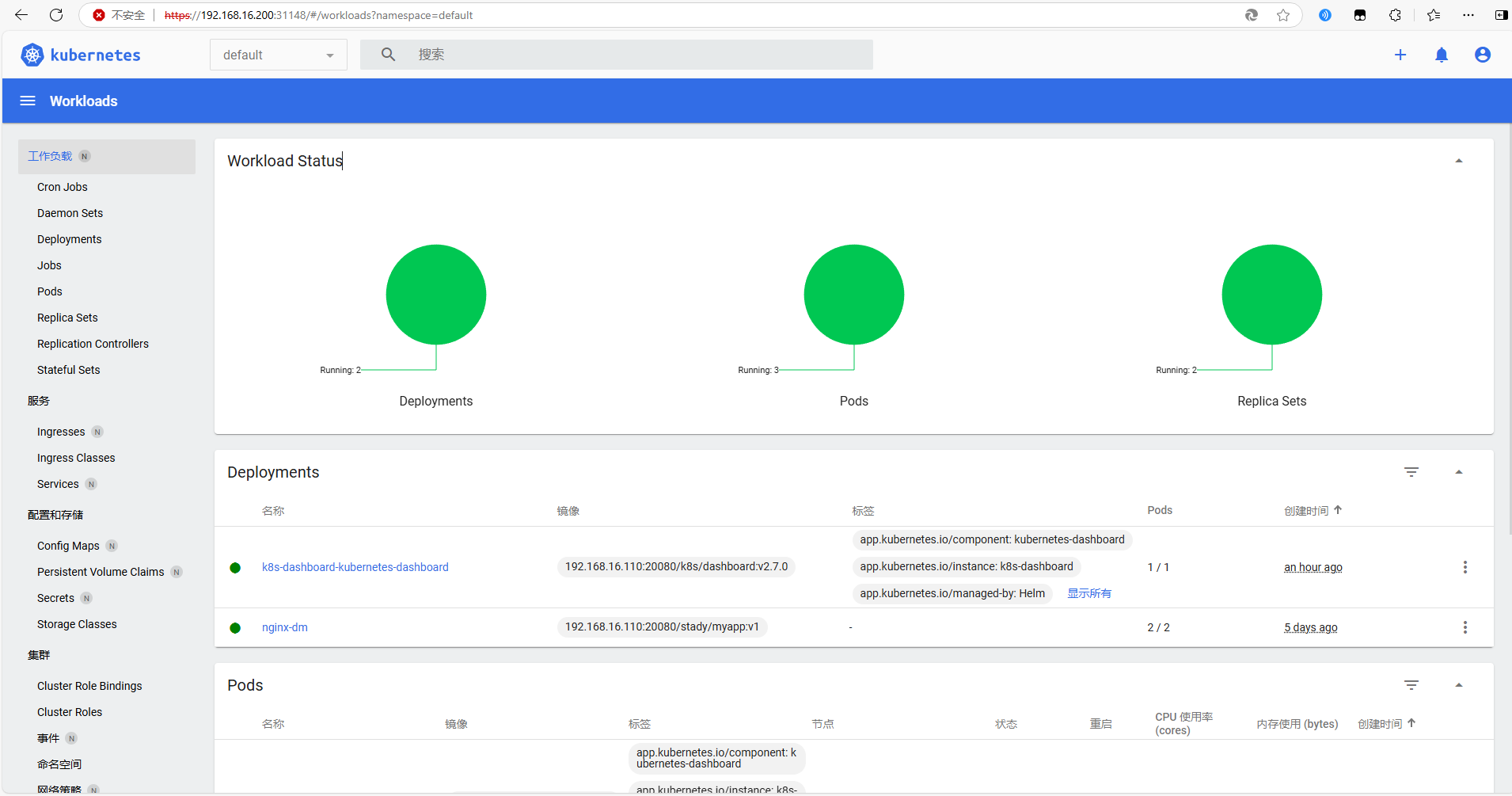
常用工具部署 使用Helm部署dashboard 1 2 3 4 5 helm install k8s-dashboard myrepo/kubernetes-dashboard --version 5.11.0 \ --set image.repository=192.168.16.110:20080/k8s/dashboard \ --set image.tag=v2.7.0 \ --set metricsScraper.image.repository=192.168.16.110:20080/k8s/metrics-scraper \ --set metricsScraper.image.tag=v1.0.8
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@master helm]# helm install k8s-dashboard myrepo/kubernetes-dashboard --version 5.11.0 \ > --set image.repository=192.168.16.110:20080/k8s/dashboard \ > --set image.tag=v2.7.0 \ > --set metricsScraper.image.repository=192.168.16.110:20080/k8s/metrics-scraper \ > --set metricsScraper.image.tag=v1.0.8 NAME: k8s-dashboard LAST DEPLOYED: Sun Dec 29 19:06:32 2024 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: ********************************************************************************* *** PLEASE BE PATIENT: kubernetes-dashboard may take a few minutes to install *** ********************************************************************************* Get the Kubernetes Dashboard URL by running: export POD_NAME=$(kubectl get pods -n default -l "app.kubernetes.io/name=kubernetes-dashboard,app.kubernetes.io/instance=k8s-dashboard" -o jsonpath="{.items[0].metadata.name}") echo https://127.0.0.1:8443/ kubectl -n default port-forward $POD_NAME 8443:8443 [root@master helm]# [root@master helm]#
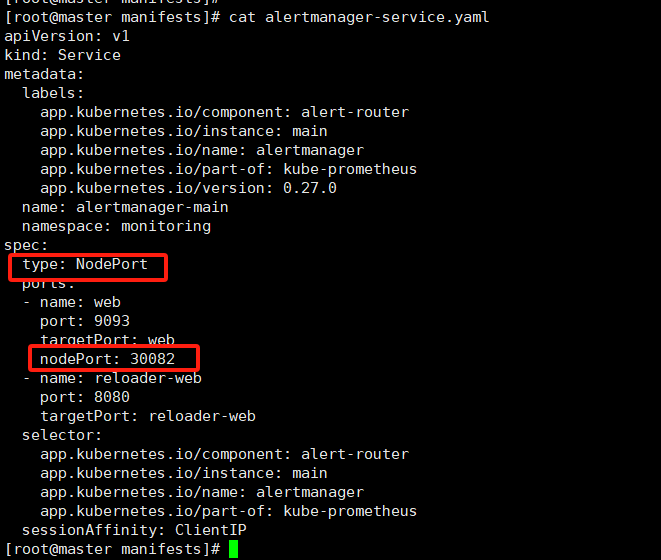
编辑 dashboard 将 type: ClusterIP 改为 type: NodePort
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 [root@master helm]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE k8s-dashboard-kubernetes-dashboard ClusterIP 10.99.202.36 <none> 443/TCP 26m kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 50d my-service-1 ExternalName <none> www.baidu.com <none> 6d21h myapp ClusterIP 10.97.220.149 <none> 80/TCP 6d21h myapp-headless ClusterIP None <none> 80/TCP 6d21h myapp-nodeport NodePort 10.99.67.70 <none> 80:31635/TCP 6d21h nginx-svc ClusterIP 10.104.90.73 <none> 80/TCP 5d20h [root@master helm]# kubectl edit svc k8s-dashboard-kubernetes-dashboard # Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: v1 kind: Service metadata: annotations: meta.helm.sh/release-name: k8s-dashboard meta.helm.sh/release-namespace: default creationTimestamp: "2024-12-29T11:06:32Z" labels: app.kubernetes.io/component: kubernetes-dashboard app.kubernetes.io/instance: k8s-dashboard app.kubernetes.io/managed-by: Helm app.kubernetes.io/name: kubernetes-dashboard app.kubernetes.io/version: 2.7.0 helm.sh/chart: kubernetes-dashboard-5.11.0 kubernetes.io/cluster-service: "true" name: k8s-dashboard-kubernetes-dashboard namespace: default resourceVersion: "371630" uid: cda39119-a868-4485-8f8f-53db9b21ba86 spec: clusterIP: 10.99.202.36 clusterIPs: - 10.99.202.36 internalTrafficPolicy: Cluster ipFamilies: - IPv4 ipFamilyPolicy: SingleStack ports: - name: https port: 443 protocol: TCP targetPort: https selector: app.kubernetes.io/component: kubernetes-dashboard app.kubernetes.io/instance: k8s-dashboard app.kubernetes.io/name: kubernetes-dashboard sessionAffinity: None type: NodePort status: loadBalancer: {}
保存退出,查看 k8s-dashboard-kubernetes-dashboard 的类型已经修改为 NodePort
1 2 3 4 5 6 7 8 9 10 11 [root@master helm]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE k8s-dashboard-kubernetes-dashboard NodePort 10.99.202.36 <none> 443:31148/TCP 30m kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 50d my-service-1 ExternalName <none> www.baidu.com <none> 6d21h myapp ClusterIP 10.97.220.149 <none> 80/TCP 6d21h myapp-headless ClusterIP None <none> 80/TCP 6d21h myapp-nodeport NodePort 10.99.67.70 <none> 80:31635/TCP 6d21h nginx-svc ClusterIP 10.104.90.73 <none> 80/TCP 5d20h [root@master helm]#
可以访问 https://192.168.16.200:31148
创建登录用户的token
构造配置文件 k8s-admin-user.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: default --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: default --- apiVersion: v1 kind: Secret metadata: name: admin-user-token namespace: default annotations: kubernetes.io/service-account.name: admin-user type: kubernetes.io/service-account-token
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [root@master helm]# kubectl apply -f k8s-admin-user.yaml serviceaccount/admin-user created clusterrolebinding.rbac.authorization.k8s.io/admin-user created secret/admin-user-token created [root@master helm]# kubectl get secret NAME TYPE DATA AGE admin-user-token kubernetes.io/service-account-token 3 5s ... [root@master helm]# kubectl get secret admin-user-token NAME TYPE DATA AGE admin-user-token kubernetes.io/service-account-token 3 10s [root@master helm]# kubectl describe secret admin-user-token Name: admin-user-token Namespace: default Labels: <none> Annotations: kubernetes.io/service-account.name: admin-user kubernetes.io/service-account.uid: 95b832b2-c5a0-4b90-901e-f8ec0bb8c765 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1107 bytes namespace: 7 bytes token: eyJhbGciOiJSUzI1NiIsImtpZCI6Ikt4RTFCbWl1ZVBxbDZmNjZwX0dGT3ozRmRKbXp5cElSRTl5ZUs4VFRXWkUifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZWZhdWx0Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6ImFkbWluLXVzZXItdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiYWRtaW4tdXNlciIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6Ijk1YjgzMmIyLWM1YTAtNGI5MC05MDFlLWY4ZWMwYmI4Yzc2NSIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpkZWZhdWx0OmFkbWluLXVzZXIifQ.QBStWk_BfZNUAkvzjc9LZzfo92LSMcivhzwZfmjI3TLd6aLeXwLvN3ifBqAiDBAHSnZnBmI9Du8f4EycXc8RJPnb_1QbVH1gbTiPnFeVl5qrMOoJKK5jITeBDCo5d8whBiiTR5zPLA-K41xGP89uD-GNbFJlb0FmEFWWePgcQbFmi_OKKnNwwuXmt04H2s7LffrpTNGApnx8zdYF2MtVk_Z-ZC6y3y-ZJ_L_tlIn6yJfKuIxeEZQpUCnxI1ypm3vBUXGyI2QOh7AOkpfBBLXtMBkzcP9NFBuv-CJz-pYJVQQ6h1ScvkUtH2Jf89YyPVB6QJLpKMK6lRi20mPb_a4YA [root@master helm]#
将token字段复制到页面上的 token 选项中 点击登录
当前token默认15分钟会过期. 如果想要设置成永久不过期需要增加启动参数 –token-ttl=0.1 kubectl edit deployment k8s-dashboard-kubernetes-dashboard
1 2 3 4 5 6 7 8 9 ... spec: containers: - args: - --namespace=default - --auto-generate-certificates - --metrics-provider=none - --token-ttl=0 ...
使用Helm部署metrics-server etricServer :是 kubernetes 集群资源使用情况的聚合器,收集数据给 kubernetes 集群内使用,如kubectl,hpa,scheduler 等。
当前k8s 版本是 1.28 , 匹配的chart包可以选择 3.8.4
增加仓库
1 2 helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/ helm search repo metrics-server --versions
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [root@lqz-test-demo pkg]# helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/ "metrics-server" has been added to your repositories [root@lqz-test-demo pkg]# [root@lqz-test-demo pkg]# helm repo update Hang tight while we grab the latest from your chart repositories... ...Successfully got an update from the "aliyun" chart repository ...Successfully got an update from the "metrics-server" chart repository ...Successfully got an update from the "dashboard-repo" chart repository Update Complete. ⎈Happy Helming!⎈ [root@lqz-test-demo pkg]# helm search repo metrics-server --versions NAME CHART VERSION APP VERSION DESCRIPTION metrics-server/metrics-server 3.12.2 0.7.2 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.12.1 0.7.1 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.12.0 0.7.0 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.11.0 0.6.4 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.10.0 0.6.3 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.9.0 0.6.3 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.8.4 0.6.2 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.8.3 0.6.2 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.8.2 0.6.1 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.8.1 0.6.1 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.8.0 0.6.0 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.7.0 0.5.2 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.6.0 0.5.1 Metrics Server is a scalable, efficient source ... metrics-server/metrics-server 3.5.0 0.5.0 Metrics Server is a scalable, efficient source ...
下载并上传如内网 chart仓库
1 2 helm pull metrics-server/metrics-server --version 3.8.4 curl -F "chart=@./metrics-server-3.8.4.tgz" http://192.168.16.110:38080/api/charts
1 2 3 [root@lqz-test-demo pkg]# helm pull metrics-server/metrics-server --version 3.8.4 [root@lqz-test-demo pkg]# curl -F "chart=@./metrics-server-3.8.4.tgz" http://192.168.16.110:38080/api/charts {"saved":true}[root@lqz-test-demo pkg]#
内网通过 chart 安装
创建一个默认参数的配置文件 temp-values.yaml
在原有的基础上增加一个 参数 –kubelet-insecure-tls
1 2 3 4 5 6 7 defaultArgs: - --cert-dir=/tmp - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --kubelet-use-node-status-port - --metric-resolution=15s - --kubelet-insecure-tls
1 2 3 helm install metrics-server myrepo/metrics-server --version 3.8.4 \ --set image.repository=192.168.16.110:20080/k8s/metrics-server \ -f temp-values.yaml
安装成功 ,可以查看pod所占用的cpu 与内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 [root@master helm]# helm install metrics-server myrepo/metrics-server --version 3.8.4 \ > --set image.repository=192.168.16.110:20080/k8s/metrics-server \ > -f temp-values.yaml NAME: metrics-server LAST DEPLOYED: Sun Dec 29 21:35:48 2024 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: *********************************************************************** * Metrics Server * *********************************************************************** Chart version: 3.8.4 App version: 0.6.2 Image tag: 192.168.16.110:20080/k8s/metrics-server:v0.6.2 *********************************************************************** [root@master helm]# kubectl get pod NAME READY STATUS RESTARTS AGE k8s-dashboard-kubernetes-dashboard-7b98647d5f-ptbs4 1/1 Running 0 150m metrics-server-868cd67584-fhf78 1/1 Running 0 51s nginx-dm-56996c5fdc-kdmjj 1/1 Running 4 (20h ago) 2d22h nginx-dm-56996c5fdc-n88vt 1/1 Running 4 (20h ago) 2d23h [root@master helm]# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% master 163m 8% 972Mi 25% node1 30m 1% 542Mi 14% node2 39m 1% 679Mi 17% [root@master helm]# [root@master helm]# kubectl top pod -A NAMESPACE NAME CPU(cores) MEMORY(bytes) default k8s-dashboard-kubernetes-dashboard-ddcdcc98-xs779 10m 46Mi default metrics-server-868cd67584-fhf78 5m 25Mi default nginx-dm-56996c5fdc-kdmjj 0m 5Mi default nginx-dm-56996c5fdc-n88vt 0m 4Mi ingress-nginx ingress-nginx-controller-749f794b9-hd862 2m 155Mi kube-flannel kube-flannel-ds-b55zx 7m 58Mi kube-flannel kube-flannel-ds-c22v9 5m 60Mi kube-flannel kube-flannel-ds-vv4c8 5m 18Mi kube-system coredns-66f779496c-mgdkr 1m 22Mi kube-system coredns-66f779496c-rp7c8 1m 62Mi kube-system etcd-master 17m 413Mi kube-system kube-apiserver-master 44m 409Mi kube-system kube-controller-manager-master 12m 164Mi kube-system kube-proxy-47xsf 1m 79Mi kube-system kube-proxy-4rgzh 1m 76Mi kube-system kube-proxy-gf8hr 1m 76Mi kube-system kube-scheduler-master 2m 77Mi [root@master helm]#
遇到的故障1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 [root@master helm]# helm install metrics-server myrepo/metrics-server --version 3.8.4 \ > --set image.repository=192.168.16.110:20080/k8s/metrics-server NAME: metrics-server LAST DEPLOYED: Sun Dec 29 21:11:36 2024 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: *********************************************************************** * Metrics Server * *********************************************************************** Chart version: 3.8.4 App version: 0.6.2 Image tag: 192.168.16.110:20080/k8s/metrics-server:v0.6.2 *********************************************************************** [root@master helm]# kubectl get pod NAME READY STATUS RESTARTS AGE k8s-dashboard-kubernetes-dashboard-7b98647d5f-ptbs4 1/1 Running 0 125m metrics-server-77bf9f5f89-pqg2p 0/1 Running 0 27s nginx-dm-56996c5fdc-kdmjj 1/1 Running 4 (20h ago) 2d22h nginx-dm-56996c5fdc-n88vt 1/1 Running 4 (20h ago) 2d23h [root@master helm]# kubectl get pod NAME READY STATUS RESTARTS AGE k8s-dashboard-kubernetes-dashboard-7b98647d5f-ptbs4 1/1 Running 0 125m metrics-server-77bf9f5f89-pqg2p 0/1 Running 0 37s nginx-dm-56996c5fdc-kdmjj 1/1 Running 4 (20h ago) 2d22h nginx-dm-56996c5fdc-n88vt 1/1 Running 4 (20h ago) 2d23h [root@master helm]# kubectl top node error: Metrics API not available [root@master helm]# kubectl get pod NAME READY STATUS RESTARTS AGE k8s-dashboard-kubernetes-dashboard-7b98647d5f-ptbs4 1/1 Running 0 126m metrics-server-77bf9f5f89-pqg2p 0/1 Running 0 87s nginx-dm-56996c5fdc-kdmjj 1/1 Running 4 (20h ago) 2d22h nginx-dm-56996c5fdc-n88vt 1/1 Running 4 (20h ago) 2d23h [root@master helm]# kubectl describe metrics-server-77bf9f5f89-pqg2p error: the server doesn't have a resource type "metrics-server-77bf9f5f89-pqg2p" [root@master helm]# kubectl describe pod metrics-server-77bf9f5f89-pqg2p Name: metrics-server-77bf9f5f89-pqg2p Namespace: default Priority: 2000000000 Priority Class Name: system-cluster-critical Service Account: metrics-server Node: node1/192.168.16.201 Start Time: Sun, 29 Dec 2024 21:11:36 +0800 Labels: app.kubernetes.io/instance=metrics-server app.kubernetes.io/name=metrics-server pod-template-hash=77bf9f5f89 Annotations: <none> Status: Running IP: 10.244.1.146 IPs: IP: 10.244.1.146 Controlled By: ReplicaSet/metrics-server-77bf9f5f89 Containers: metrics-server: Container ID: docker://9db4808219d4afb94b7fa086165482c96373d6104b42a7155a303f0adb14a085 Image: 192.168.16.110:20080/k8s/metrics-server:v0.6.2 Image ID: docker-pullable://192.168.16.110:20080/k8s/metrics-server@sha256:0542aeb0025f6dd4f75e100ca14d7abdbe0725c75783d13c35e82d391f4735bc Port: 4443/TCP Host Port: 0/TCP Args: --secure-port=4443 --cert-dir=/tmp --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname --kubelet-use-node-status-port --metric-resolution=15s State: Running Started: Sun, 29 Dec 2024 21:11:42 +0800 Ready: False Restart Count: 0 Liveness: http-get https://:https/livez delay=0s timeout=1s period=10s #success=1 #failure=3 Readiness: http-get https://:https/readyz delay=20s timeout=1s period=10s #success=1 #failure=3 Environment: <none> Mounts: /tmp from tmp (rw) /var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-djdsh (ro) Conditions: Type Status Initialized True Ready False ContainersReady False PodScheduled True Volumes: tmp: Type: EmptyDir (a temporary directory that shares a pod's lifetime) Medium: SizeLimit: <unset> kube-api-access-djdsh: Type: Projected (a volume that contains injected data from multiple sources) TokenExpirationSeconds: 3607 ConfigMapName: kube-root-ca.crt ConfigMapOptional: <nil> DownwardAPI: true QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s node.kubernetes.io/unreachable:NoExecute op=Exists for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 99s default-scheduler Successfully assigned default/metrics-server-77bf9f5f89-pqg2p to node1 Normal Pulling 97s kubelet Pulling image "192.168.16.110:20080/k8s/metrics-server:v0.6.2" Normal Pulled 95s kubelet Successfully pulled image "192.168.16.110:20080/k8s/metrics-server:v0.6.2" in 2.49s (2.49s including waiting) Normal Created 94s kubelet Created container metrics-server Normal Started 93s kubelet Started container metrics-server Warning Unhealthy 8s (x8 over 68s) kubelet Readiness probe failed: HTTP probe failed with statuscode: 500 [root@master helm]# [root@master helm]# kubectl logs metrics-server-77bf9f5f89-pqg2p I1229 13:11:42.567091 1 serving.go:342] Generated self-signed cert (/tmp/apiserver.crt, /tmp/apiserver.key) I1229 13:11:43.147794 1 requestheader_controller.go:169] Starting RequestHeaderAuthRequestController I1229 13:11:43.147821 1 shared_informer.go:240] Waiting for caches to sync for RequestHeaderAuthRequestController I1229 13:11:43.147887 1 configmap_cafile_content.go:201] "Starting controller" name="client-ca::kube-system::extension-apiserver-authentication::client-ca-file" I1229 13:11:43.147902 1 shared_informer.go:240] Waiting for caches to sync for client-ca::kube-system::extension-apiserver-authentication::client-ca-file I1229 13:11:43.147927 1 configmap_cafile_content.go:201] "Starting controller" name="client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file" I1229 13:11:43.147935 1 shared_informer.go:240] Waiting for caches to sync for client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file I1229 13:11:43.148580 1 secure_serving.go:266] Serving securely on [::]:4443 I1229 13:11:43.148629 1 dynamic_serving_content.go:131] "Starting controller" name="serving-cert::/tmp/apiserver.crt::/tmp/apiserver.key" I1229 13:11:43.154786 1 tlsconfig.go:240] "Starting DynamicServingCertificateController" W1229 13:11:43.154994 1 shared_informer.go:372] The sharedIndexInformer has started, run more than once is not allowed E1229 13:11:43.261055 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.202:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.202 because it doesn't contain any IP SANs" node="node2" I1229 13:11:43.266215 1 shared_informer.go:247] Caches are synced for client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file I1229 13:11:43.266245 1 shared_informer.go:247] Caches are synced for RequestHeaderAuthRequestController I1229 13:11:43.266288 1 shared_informer.go:247] Caches are synced for client-ca::kube-system::extension-apiserver-authentication::client-ca-file E1229 13:11:43.266487 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.201:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.201 because it doesn't contain any IP SANs" node="node1" E1229 13:11:43.269494 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.200:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.200 because it doesn't contain any IP SANs" node="master" E1229 13:11:58.154061 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.200:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.200 because it doesn't contain any IP SANs" node="master" E1229 13:11:58.155073 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.201:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.201 because it doesn't contain any IP SANs" node="node1" E1229 13:11:58.156782 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.202:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.202 because it doesn't contain any IP SANs" node="node2" I1229 13:12:07.322217 1 server.go:187] "Failed probe" probe="metric-storage-ready" err="no metrics to serve" E1229 13:12:13.148989 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.202:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.202 because it doesn't contain any IP SANs" node="node2" E1229 13:12:13.158791 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.201:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.201 because it doesn't contain any IP SANs" node="node1" E1229 13:12:13.159009 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.200:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.200 because it doesn't contain any IP SANs" node="master" I1229 13:12:17.320166 1 server.go:187] "Failed probe" probe="metric-storage-ready" err="no metrics to serve" I1229 13:12:27.324486 1 server.go:187] "Failed probe" probe="metric-storage-ready" err="no metrics to serve" E1229 13:12:28.142888 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.202:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.202 because it doesn't contain any IP SANs" node="node2" E1229 13:12:28.143171 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.200:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.200 because it doesn't contain any IP SANs" node="master" E1229 13:12:28.155537 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.201:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.201 because it doesn't contain any IP SANs" node="node1" I1229 13:12:37.320175 1 server.go:187] "Failed probe" probe="metric-storage-ready" err="no metrics to serve" E1229 13:12:43.145359 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.201:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.201 because it doesn't contain any IP SANs" node="node1" E1229 13:12:43.147513 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.202:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.202 because it doesn't contain any IP SANs" node="node2" E1229 13:12:43.147828 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.200:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.200 because it doesn't contain any IP SANs" node="master" I1229 13:12:47.320303 1 server.go:187] "Failed probe" probe="metric-storage-ready" err="no metrics to serve" I1229 13:12:57.321628 1 server.go:187] "Failed probe" probe="metric-storage-ready" err="no metrics to serve" E1229 13:12:58.149277 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.201:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.201 because it doesn't contain any IP SANs" node="node1" E1229 13:12:58.160340 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.200:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.200 because it doesn't contain any IP SANs" node="master" E1229 13:12:58.165040 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.202:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.202 because it doesn't contain any IP SANs" node="node2" I1229 13:13:07.324079 1 server.go:187] "Failed probe" probe="metric-storage-ready" err="no metrics to serve" I1229 13:13:07.965018 1 server.go:187] "Failed probe" probe="metric-storage-ready" err="no metrics to serve" E1229 13:13:13.152192 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.202:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.202 because it doesn't contain any IP SANs" node="node2" E1229 13:13:13.156025 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.200:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.200 because it doesn't contain any IP SANs" node="master" E1229 13:13:13.160081 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.16.201:10250/metrics/resource\": x509: cannot validate certificate for 192.168.16.201 because it doesn't contain any IP SANs" node="node1" I1229 13:13:17.319809 1 server.go:187] "Failed probe" probe="metric-storage-ready" err="no metrics to serve" [root@master helm]#
部署prometheus 部署开源项目prometheus-operator/kube-prometheus
需要kebulet z支持如下两个参数
1 2 * --authentication-token-webhook=true此标志使令牌可用于对 kubelet 进行身份验证。也可以通过将 kubelet 配置值设置为 来启用此功能。ServiceAccountauthentication.webhook.enabledtrue * --authorization-mode=Webhook此标志使 kubelet 能够使用 API 执行 RBAC 请求,以确定是否允许请求实体(在本例中为 Prometheus)访问资源,特别是对于此项目的端点。也可以通过将 kubelet 配置值设置为 来启用此功能。/metricsauthorization.modeWebhook
修改启动配置文件增加这两个参数
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@master kubelet.service.d]# cat /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf # Note: This dropin only works with kubeadm and kubelet v1.11+ [Service] Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --authorization-mode=Webhook --authentication-token-webhook=true " Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml" # This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env # This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use # the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file. EnvironmentFile=-/etc/sysconfig/kubelet ExecStart= ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS [root@master kubelet.service.d]#
重启服务
1 2 systemctl daemon-reload systemctl restart kubelet.service
下载源码
1 2 3 wget http://192.168.16.110:9080/other/kube-prometheus-0.14.0.tar.gz tar -xvzf kube-prometheus-0.14.0.tar.gz cd kube-prometheus-0.14.0
查看需要的镜像 , 提前准备好, 导入到内网私有仓库
1 2 grep 'image:' *.yaml grep -rn 'quay.io' *
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master manifests]# ls -ld *deployment* -rw-rw-r-- 1 root root 3645 9月 12 15:45 blackboxExporter-deployment.yaml -rw-rw-r-- 1 root root 9685 9月 12 15:45 grafana-deployment.yaml -rw-rw-r-- 1 root root 3617 9月 12 15:45 kubeStateMetrics-deployment.yaml -rw-rw-r-- 1 root root 3426 9月 12 15:45 prometheusAdapter-deployment.yaml -rw-rw-r-- 1 root root 2803 9月 12 15:45 prometheusOperator-deployment.yaml [root@master manifests]# grep image: *.yaml blackboxExporter-deployment.yaml: image: quay.io/prometheus/blackbox-exporter:v0.25.0 blackboxExporter-deployment.yaml: image: ghcr.io/jimmidyson/configmap-reload:v0.13.1 blackboxExporter-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1 grafana-deployment.yaml: image: grafana/grafana:11.2.0 kubeStateMetrics-deployment.yaml: image: registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.13.0 kubeStateMetrics-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1 kubeStateMetrics-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1 prometheusAdapter-deployment.yaml: image: registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.12.0 prometheusOperator-deployment.yaml: image: quay.io/prometheus-operator/prometheus-operator:v0.76.2 prometheusOperator-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1 [root@master manifests]# grep -rn 'quay.io' * prometheusOperator-deployment.yaml:32: - --prometheus-config-reloader=quay.io/prometheus-operator/prometheus-config-reloader:v0.76.2 [root@master manifests]# pwd /data/app/k8s/helm/kube-prometheus-0.14.0/manifests [root@master manifests]#
修改镜像为内网仓库的镜像地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@master manifests]# grep 'image:' *yaml alertmanager-alertmanager.yaml: image: 192.168.16.110:20080/k8s/prometheus/alertmanager:v0.27.0 blackboxExporter-deployment.yaml: image: 192.168.16.110:20080/k8s/prometheus/blackbox-exporter:v0.25.0 blackboxExporter-deployment.yaml: image: 192.168.16.110:20080/k8s/jimmidyson/configmap-reload:v0.13.1 blackboxExporter-deployment.yaml: image: 192.168.16.110:20080/k8s/brancz/kube-rbac-proxy:v0.18.1 grafana-deployment.yaml: image: 192.168.16.110:20080/k8s/grafana:11.2.0 kubeStateMetrics-deployment.yaml: image: 192.168.16.110:20080/k8s/kube-state-metrics/kube-state-metrics:v2.13.0 kubeStateMetrics-deployment.yaml: image: 192.168.16.110:20080/k8s/brancz/kube-rbac-proxy:v0.18.1 kubeStateMetrics-deployment.yaml: image: 192.168.16.110:20080/k8s/brancz/kube-rbac-proxy:v0.18.1 nodeExporter-daemonset.yaml: image: 192.168.16.110:20080/k8s/prometheus/node-exporter:v1.8.2 nodeExporter-daemonset.yaml: image: 192.168.16.110:20080/k8s/brancz/kube-rbac-proxy:v0.18.1 prometheusAdapter-deployment.yaml: image: 192.168.16.110:20080/k8s/prometheus-adapter/prometheus-adapter:v0.12.0 prometheusOperator-deployment.yaml: image: 192.168.16.110:20080/k8s/prometheus-operator/prometheus-operator:v0.76.2 prometheusOperator-deployment.yaml: image: 192.168.16.110:20080/k8s/brancz/kube-rbac-proxy:v0.18.1 prometheus-prometheus.yaml: image: 192.168.16.110:20080/k8s/prometheus/prometheus:v2.54.1 [root@master manifests]#
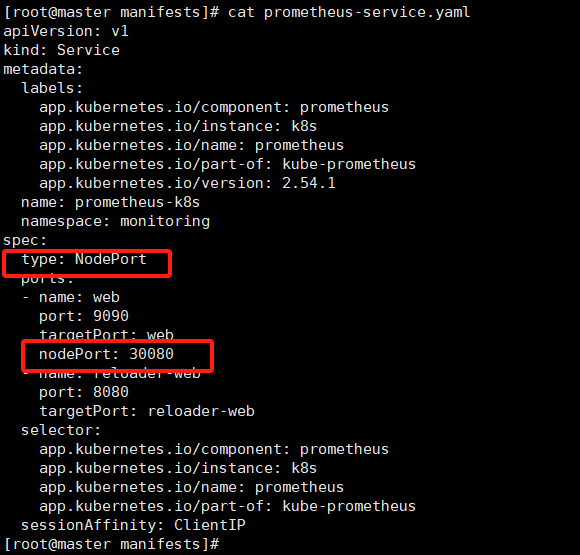
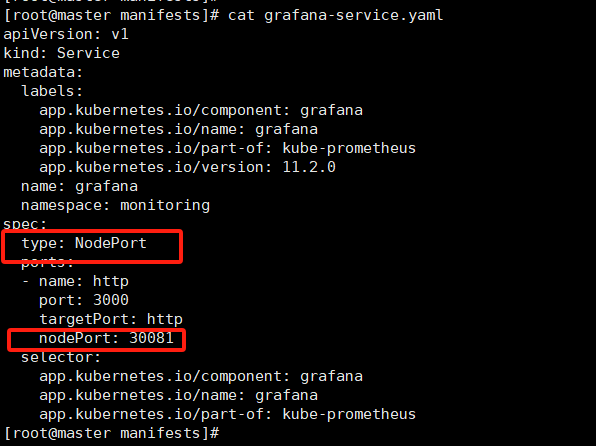
修改 prometheus/grafana/alertmanager 对外开放的端口
提前卸载 metrics-server
1 2 3 4 5 6 7 8 9 10 11 [root@master helm]# helm ls NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION k8s-dashboard default 1 2024-12-29 19:06:32.1620968 +0800 CST deployed kubernetes-dashboard-5.11.0 2.7.0 metrics-server default 1 2024-12-29 21:35:48.462192601 +0800 CST deployed metrics-server-3.8.4 0.6.2 [root@master helm]# helm uninstall metrics-server release "metrics-server" uninstalled [root@master helm]# helm ls NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION k8s-dashboard default 1 2024-12-29 19:06:32.1620968 +0800 CST deployed kubernetes-dashboard-5.11.0 2.7.0 [root@master helm]#
开始部署 Prometheus Operator,加上 –server-side 比较稳,不然可能会有报错
1 2 3 kubectl apply --server-side -f manifests/setup/ kubectl apply --server-side -f manifests/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 [root@master kube-prometheus-0.14.0]# kubectl apply --server-side -f manifests/setup/ customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/prometheusagents.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/scrapeconfigs.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com serverside-applied customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com serverside-applied namespace/monitoring serverside-applied [root@master kube-prometheus-0.14.0]# kubectl apply -f manifests/ alertmanager.monitoring.coreos.com/main created networkpolicy.networking.k8s.io/alertmanager-main created poddisruptionbudget.policy/alertmanager-main created prometheusrule.monitoring.coreos.com/alertmanager-main-rules created secret/alertmanager-main created service/alertmanager-main created serviceaccount/alertmanager-main created servicemonitor.monitoring.coreos.com/alertmanager-main created clusterrole.rbac.authorization.k8s.io/blackbox-exporter created clusterrolebinding.rbac.authorization.k8s.io/blackbox-exporter created configmap/blackbox-exporter-configuration created deployment.apps/blackbox-exporter created networkpolicy.networking.k8s.io/blackbox-exporter created service/blackbox-exporter created serviceaccount/blackbox-exporter created servicemonitor.monitoring.coreos.com/blackbox-exporter created secret/grafana-config created secret/grafana-datasources created configmap/grafana-dashboard-alertmanager-overview created configmap/grafana-dashboard-apiserver created configmap/grafana-dashboard-cluster-total created configmap/grafana-dashboard-controller-manager created configmap/grafana-dashboard-grafana-overview created configmap/grafana-dashboard-k8s-resources-cluster created configmap/grafana-dashboard-k8s-resources-multicluster created configmap/grafana-dashboard-k8s-resources-namespace created configmap/grafana-dashboard-k8s-resources-node created configmap/grafana-dashboard-k8s-resources-pod created configmap/grafana-dashboard-k8s-resources-workload created configmap/grafana-dashboard-k8s-resources-workloads-namespace created configmap/grafana-dashboard-kubelet created configmap/grafana-dashboard-namespace-by-pod created configmap/grafana-dashboard-namespace-by-workload created configmap/grafana-dashboard-node-cluster-rsrc-use created configmap/grafana-dashboard-node-rsrc-use created configmap/grafana-dashboard-nodes-darwin created configmap/grafana-dashboard-nodes created configmap/grafana-dashboard-persistentvolumesusage created configmap/grafana-dashboard-pod-total created configmap/grafana-dashboard-prometheus-remote-write created configmap/grafana-dashboard-prometheus created configmap/grafana-dashboard-proxy created configmap/grafana-dashboard-scheduler created configmap/grafana-dashboard-workload-total created configmap/grafana-dashboards created deployment.apps/grafana created networkpolicy.networking.k8s.io/grafana created prometheusrule.monitoring.coreos.com/grafana-rules created service/grafana created serviceaccount/grafana created servicemonitor.monitoring.coreos.com/grafana created prometheusrule.monitoring.coreos.com/kube-prometheus-rules created clusterrole.rbac.authorization.k8s.io/kube-state-metrics created clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created deployment.apps/kube-state-metrics created networkpolicy.networking.k8s.io/kube-state-metrics created prometheusrule.monitoring.coreos.com/kube-state-metrics-rules created service/kube-state-metrics created serviceaccount/kube-state-metrics created servicemonitor.monitoring.coreos.com/kube-state-metrics created prometheusrule.monitoring.coreos.com/kubernetes-monitoring-rules created servicemonitor.monitoring.coreos.com/kube-apiserver created servicemonitor.monitoring.coreos.com/coredns created servicemonitor.monitoring.coreos.com/kube-controller-manager created servicemonitor.monitoring.coreos.com/kube-scheduler created servicemonitor.monitoring.coreos.com/kubelet created clusterrole.rbac.authorization.k8s.io/node-exporter created clusterrolebinding.rbac.authorization.k8s.io/node-exporter created daemonset.apps/node-exporter created networkpolicy.networking.k8s.io/node-exporter created prometheusrule.monitoring.coreos.com/node-exporter-rules created service/node-exporter created serviceaccount/node-exporter created servicemonitor.monitoring.coreos.com/node-exporter created clusterrole.rbac.authorization.k8s.io/prometheus-k8s created clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created networkpolicy.networking.k8s.io/prometheus-k8s created poddisruptionbudget.policy/prometheus-k8s created prometheus.monitoring.coreos.com/k8s created prometheusrule.monitoring.coreos.com/prometheus-k8s-prometheus-rules created rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created rolebinding.rbac.authorization.k8s.io/prometheus-k8s created rolebinding.rbac.authorization.k8s.io/prometheus-k8s created rolebinding.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s-config created role.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s created role.rbac.authorization.k8s.io/prometheus-k8s created service/prometheus-k8s created serviceaccount/prometheus-k8s created servicemonitor.monitoring.coreos.com/prometheus-k8s created apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created clusterrole.rbac.authorization.k8s.io/prometheus-adapter created clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created configmap/adapter-config created deployment.apps/prometheus-adapter created networkpolicy.networking.k8s.io/prometheus-adapter created poddisruptionbudget.policy/prometheus-adapter created rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created service/prometheus-adapter created serviceaccount/prometheus-adapter created servicemonitor.monitoring.coreos.com/prometheus-adapter created clusterrole.rbac.authorization.k8s.io/prometheus-operator created clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created deployment.apps/prometheus-operator created networkpolicy.networking.k8s.io/prometheus-operator created prometheusrule.monitoring.coreos.com/prometheus-operator-rules created service/prometheus-operator created serviceaccount/prometheus-operator created servicemonitor.monitoring.coreos.com/prometheus-operator created [root@master kube-prometheus-0.14.0]#
查看结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 [root@master kube-prometheus-0.14.0]# kubectl get pod -A NAMESPACE NAME READY STATUS RESTARTS AGE default k8s-dashboard-kubernetes-dashboard-ddcdcc98-xs779 1/1 Running 1 (20h ago) 23h default nginx-dm-56996c5fdc-kdmjj 1/1 Running 5 (20h ago) 3d22h default nginx-dm-56996c5fdc-n88vt 1/1 Running 5 (20h ago) 3d23h ingress-nginx ingress-nginx-admission-patch-d9ghq 0/1 Completed 0 6d22h ingress-nginx ingress-nginx-controller-749f794b9-hd862 1/1 Running 4 (20h ago) 3d22h kube-flannel kube-flannel-ds-b55zx 1/1 Running 5 (20h ago) 3d21h kube-flannel kube-flannel-ds-c22v9 1/1 Running 23 (99m ago) 51d kube-flannel kube-flannel-ds-vv4c8 1/1 Running 28 (99m ago) 51d kube-system coredns-66f779496c-mgdkr 1/1 Running 20 (20h ago) 51d kube-system coredns-66f779496c-rp7c8 1/1 Running 20 (20h ago) 51d kube-system etcd-master 1/1 Running 20 (20h ago) 51d kube-system kube-apiserver-master 1/1 Running 20 (20h ago) 51d kube-system kube-controller-manager-master 1/1 Running 22 (20h ago) 51d kube-system kube-proxy-47xsf 1/1 Running 20 (20h ago) 51d kube-system kube-proxy-4rgzh 1/1 Running 20 (20h ago) 51d kube-system kube-proxy-gf8hr 1/1 Running 20 (20h ago) 51d kube-system kube-scheduler-master 1/1 Running 21 (20h ago) 51d monitoring alertmanager-main-0 2/2 Running 0 85s monitoring alertmanager-main-1 2/2 Running 0 85s monitoring alertmanager-main-2 2/2 Running 0 85s monitoring blackbox-exporter-5bccc4647f-5hr6q 3/3 Running 0 2m55s monitoring grafana-5bccbb4458-gf7w7 1/1 Running 0 2m48s monitoring kube-state-metrics-6476556476-txf2m 3/3 Running 0 2m47s monitoring node-exporter-rc4dk 2/2 Running 0 2m46s monitoring node-exporter-vkqlb 2/2 Running 0 2m46s monitoring node-exporter-w599t 2/2 Running 0 2m46s monitoring prometheus-adapter-57568fff57-fdvrn 1/1 Running 0 2m44s monitoring prometheus-adapter-57568fff57-t7xvd 1/1 Running 0 2m44s monitoring prometheus-k8s-0 2/2 Running 0 83s monitoring prometheus-k8s-1 2/2 Running 0 83s monitoring prometheus-operator-58b74c7fd4-2bdlb 2/2 Running 0 2m44s [root@master kube-prometheus-0.14.0]#
登录浏览器打开 prometheus
http://192.168.16.200:30080
登录浏览器打开 grafana
http://192.168.16.200:30081
登录浏览器打开 alertmanager
http://192.168.16.200:30082
grafana登录的默认是密码是 admin/admin
安装完之后默认配置了一些k8s的监控大屏 可以随意查看
至此监控平台部署完成.
参考: 官方文档
HPA 案例验证 hpa-example 是一个性能测试的容器
创建一个 Deployment /Service 配置文件 hpaDemo.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 apiVersion: apps/v1 kind: Deployment metadata: name: php-apache spec: selector: matchLabels: app: php-apache replicas: 1 template: metadata: labels: app: php-apache spec: containers: - name: php-apache image: 192.168.16.110:20080/stady/hpa-example:latest resources: requests: cpu: 200m ports: - containerPort: 80 --- kind: Service apiVersion: v1 metadata: name: php-service spec: ports: - protocol: TCP port: 80 targetPort: 80 selector: app: php-apache
1 kubectl apply -f hpaDemo.yaml
1 2 3 4 5 6 7 8 [root@master helm]# kubectl apply -f hpaDemo.yaml deployment.apps/php-apache created k8s-dashboard-kubernetes-dashboard-ddcdcc98-xs779 1/1 Running 1 (22h ago) 24h nginx-dm-56996c5fdc-kdmjj 1/1 Running 5 (22h ago) 3d23h nginx-dm-56996c5fdc-n88vt 1/1 Running 5 (22h ago) 4d php-apache-675bc649f5-tcb2w 1/1 Running 0 37s [root@master helm]#
创建HPA控制器 1 kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
稍等一下 待TARGETS 获取到信息 0%/50% (当前负载/需要扩容的负载)
1 2 3 4 5 6 7 8 9 10 11 12 [root@master helm]# kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10 horizontalpodautoscaler.autoscaling/php-apache autoscaled [root@master helm]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache <unknown>/50% 1 10 0 1s [root@master helm]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache <unknown>/50% 1 10 0 4s [root@master helm]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 0%/50% 1 10 1 16s [root@master helm]#
增加负载,查看负载节点数目 开启busybox并进入该pod
1 kubectl run -i --tty load-generator --image=192.168.16.110:20080/stady/busybox:1.28.3 /bin/sh
1 2 3 4 [root@master helm]# kubectl run -i --tty load-generator --image=192.168.16.110:20080/stady/busybox:1.28.3 /bin/sh If you don't see a command prompt, try pressing enter. / # / #
开始请求下载刚才部署的php服务
1 while true; do wget -q -O- http://php-service.default.svc.cluster.local; done
开始大量的打印OK
1 2 3 4 / # wget -q -O- http://php-service.default.svc.cluster.local OK!/ # while true; do wget -q -O- http://php-service.default.svc.cluster.local; done OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!...
重新开一个xshell窗口会看到 pod已经开始扩容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 [root@master kubelet.service.d]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 184%/50% 1 10 4 27m [root@master kubelet.service.d]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 184%/50% 1 10 4 27m [root@master kubelet.service.d]# kubectl get pod NAME READY STATUS RESTARTS AGE load-generator 1/1 Running 1 (8m43s ago) 9m39s php-apache-675bc649f5-24w6p 1/1 Running 0 25s php-apache-675bc649f5-d2h2t 1/1 Running 0 25s php-apache-675bc649f5-tcb2w 1/1 Running 1 (35h ago) 38h php-apache-675bc649f5-x9nn9 1/1 Running 0 25s [root@master kubelet.service.d]# kubectl get pod NAME READY STATUS RESTARTS AGE load-generator 1/1 Running 1 (9m18s ago) 10m php-apache-675bc649f5-24w6p 1/1 Running 0 60s php-apache-675bc649f5-886np 1/1 Running 0 30s php-apache-675bc649f5-d2h2t 1/1 Running 0 60s php-apache-675bc649f5-fng54 1/1 Running 0 30s php-apache-675bc649f5-r9s55 1/1 Running 0 30s php-apache-675bc649f5-sqbjv 1/1 Running 0 30s php-apache-675bc649f5-tcb2w 1/1 Running 1 (35h ago) 38h php-apache-675bc649f5-x9nn9 1/1 Running 0 60s [root@master kubelet.service.d]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 81%/50% 1 10 8 27m [root@master kubelet.service.d]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 81%/50% 1 10 8 27m [root@master kubelet.service.d]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 81%/50% 1 10 8 27m [root@master kubelet.service.d]#
可以看到已经扩展到8个副本.
减少负载,查看负载节点数目 将wget任务停止后可以看到pod自动缩容
1 2 3 4 5 6 7 8 [root@master kubelet.service.d]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 0%/50% 1 10 1 37m [root@master kubelet.service.d]# kubectl get pod NAME READY STATUS RESTARTS AGE load-generator 1/1 Running 1 (19m ago) 19m php-apache-675bc649f5-tcb2w 1/1 Running 1 (35h ago) 39h [root@master kubelet.service.d]#
扩容缩容哪个的日志可以查看日志.其中打印了创建pod 删除pod的记录
1 kubectl logs -n kube-system kube-controller-manager-master
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 I0101 04:13:08.286601 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="monitoring/prometheus-operator-58b74c7fd4" duration="5.750784ms" I0101 04:13:08.286658 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="monitoring/prometheus-operator-58b74c7fd4" duration="29.75µs" I0101 04:13:08.555752 1 event.go:307] "Event occurred" object="monitoring/alertmanager-main" fieldPath="" kind="StatefulSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulCreate" message="create Pod alertmanager-main-0 in StatefulSet alertmanager-main successful" I0101 04:13:08.566288 1 event.go:307] "Event occurred" object="monitoring/alertmanager-main" fieldPath="" kind="StatefulSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulCreate" message="create Pod alertmanager-main-2 in StatefulSet alertmanager-main successful" I0101 04:13:08.566306 1 event.go:307] "Event occurred" object="monitoring/alertmanager-main" fieldPath="" kind="StatefulSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulCreate" message="create Pod alertmanager-main-1 in StatefulSet alertmanager-main successful" I0101 04:13:08.964782 1 event.go:307] "Event occurred" object="monitoring/prometheus-k8s" fieldPath="" kind="StatefulSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulCreate" message="create Pod prometheus-k8s-0 in StatefulSet prometheus-k8s successful" I0101 04:13:08.977109 1 event.go:307] "Event occurred" object="monitoring/prometheus-k8s" fieldPath="" kind="StatefulSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulCreate" message="create Pod prometheus-k8s-1 in StatefulSet prometheus-k8s successful" E0101 04:13:09.004745 1 disruption.go:630] Error syncing PodDisruptionBudget monitoring/prometheus-k8s, requeuing: Operation cannot be fulfilled on poddisruptionbudgets.policy "prometheus-k8s": the object has been modified; please apply your changes to the latest version and try again I0101 04:13:15.929408 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="monitoring/grafana-5bccbb4458" duration="8.805182ms" I0101 04:13:15.929487 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="monitoring/grafana-5bccbb4458" duration="51.712µs" I0101 04:13:16.845784 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="monitoring/prometheus-adapter-57568fff57" duration="62.009µs" I0101 04:13:16.868673 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="monitoring/prometheus-adapter-57568fff57" duration="67.46µs" I0101 04:13:17.559946 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="monitoring/prometheus-adapter-57568fff57" duration="7.031249ms" I0101 04:13:17.560143 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="monitoring/prometheus-adapter-57568fff57" duration="56.92µs" I0101 04:13:17.761507 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="monitoring/prometheus-adapter-57568fff57" duration="9.974537ms" I0101 04:13:17.761569 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="monitoring/prometheus-adapter-57568fff57" duration="40.615µs" I0101 04:13:23.946798 1 endpointslice_controller.go:310] "Error syncing endpoint slices for service, retrying" key="monitoring/alertmanager-operated" err="EndpointSlice informer cache is out of date" I0101 04:13:23.946866 1 endpointslice_controller.go:310] "Error syncing endpoint slices for service, retrying" key="monitoring/alertmanager-main" err="EndpointSlice informer cache is out of date" I0101 04:13:23.950014 1 event.go:307] "Event occurred" object="monitoring/alertmanager-main" fieldPath="" kind="Endpoints" apiVersion="v1" type="Warning" reason="FailedToUpdateEndpoint" message="Failed to update endpoint monitoring/alertmanager-main: Operation cannot be fulfilled on endpoints \"alertmanager-main\": the object has been modified; please apply your changes to the latest version and try again" I0101 04:52:29.597513 1 horizontal.go:891] "Successfully rescaled" HPA="default/php-apache" currentReplicas=1 desiredReplicas=4 reason="cpu resource utilization (percentage of request) above target" I0101 04:52:29.597735 1 event.go:307] "Event occurred" object="default/php-apache" fieldPath="" kind="HorizontalPodAutoscaler" apiVersion="autoscaling/v2" type="Normal" reason="SuccessfulRescale" message="New size: 4; reason: cpu resource utilization (percentage of request) above target" I0101 04:52:29.612407 1 event.go:307] "Event occurred" object="default/php-apache" fieldPath="" kind="Deployment" apiVersion="apps/v1" type="Normal" reason="ScalingReplicaSet" message="Scaled up replica set php-apache-675bc649f5 to 4 from 1" I0101 04:52:29.628921 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulCreate" message="Created pod: php-apache-675bc649f5-x9nn9" I0101 04:52:29.633520 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulCreate" message="Created pod: php-apache-675bc649f5-24w6p" I0101 04:52:29.633535 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulCreate" message="Created pod: php-apache-675bc649f5-d2h2t" I0101 04:52:29.650099 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="38.19655ms" I0101 04:52:29.663177 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="13.015254ms" I0101 04:52:29.663247 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="27.406µs" I0101 04:52:29.669537 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="55.172µs" I0101 04:52:29.689961 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="59.708µs" I0101 04:52:31.341805 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="9.893428ms" I0101 04:52:31.341910 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="49.486µs" I0101 04:52:45.202679 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="7.53212ms" I0101 04:52:45.202919 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="48.629µs" I0101 04:52:45.219749 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="7.156557ms" I0101 04:52:45.219802 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="22.304µs" I0101 04:52:59.626691 1 horizontal.go:891] "Successfully rescaled" HPA="default/php-apache" currentReplicas=4 desiredReplicas=8 reason="cpu resource utilization (percentage of request) above target" I0101 04:52:59.626816 1 event.go:307] "Event occurred" object="default/php-apache" fieldPath="" kind="HorizontalPodAutoscaler" apiVersion="autoscaling/v2" type="Normal" reason="SuccessfulRescale" message="New size: 8; reason: cpu resource utilization (percentage of request) above target" I0101 04:52:59.633850 1 event.go:307] "Event occurred" object="default/php-apache" fieldPath="" kind="Deployment" apiVersion="apps/v1" type="Normal" reason="ScalingReplicaSet" message="Scaled up replica set php-apache-675bc649f5 to 8 from 4" I0101 04:52:59.646379 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulCreate" message="Created pod: php-apache-675bc649f5-886np" I0101 04:52:59.683500 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulCreate" message="Created pod: php-apache-675bc649f5-r9s55" I0101 04:52:59.683515 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulCreate" message="Created pod: php-apache-675bc649f5-sqbjv" I0101 04:52:59.692969 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulCreate" message="Created pod: php-apache-675bc649f5-fng54" I0101 04:52:59.705030 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="71.554229ms" I0101 04:52:59.713440 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="8.366678ms" I0101 04:52:59.713530 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="57.213µs" I0101 04:52:59.713653 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="15.759µs" I0101 04:52:59.720846 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="37.278µs" I0101 04:53:00.565828 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="8.289102ms" I0101 04:53:00.565894 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="31.626µs" I0101 04:53:01.431649 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="8.995586ms" I0101 04:53:01.431842 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="53.948µs" I0101 04:53:01.449317 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="10.390344ms" I0101 04:53:01.449497 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="53.612µs" I0101 04:53:01.641623 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="7.151272ms" I0101 04:53:01.641694 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="38.39µs" I0101 05:01:45.099894 1 horizontal.go:891] "Successfully rescaled" HPA="default/php-apache" currentReplicas=8 desiredReplicas=1 reason="All metrics below target" I0101 05:01:45.100044 1 event.go:307] "Event occurred" object="default/php-apache" fieldPath="" kind="HorizontalPodAutoscaler" apiVersion="autoscaling/v2" type="Normal" reason="SuccessfulRescale" message="New size: 1; reason: All metrics below target" I0101 05:01:45.103175 1 event.go:307] "Event occurred" object="default/php-apache" fieldPath="" kind="Deployment" apiVersion="apps/v1" type="Normal" reason="ScalingReplicaSet" message="Scaled down replica set php-apache-675bc649f5 to 1 from 8" I0101 05:01:45.116083 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulDelete" message="Deleted pod: php-apache-675bc649f5-r9s55" I0101 05:01:45.116101 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulDelete" message="Deleted pod: php-apache-675bc649f5-886np" I0101 05:01:45.116106 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulDelete" message="Deleted pod: php-apache-675bc649f5-sqbjv" I0101 05:01:45.116110 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulDelete" message="Deleted pod: php-apache-675bc649f5-fng54" I0101 05:01:45.116114 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulDelete" message="Deleted pod: php-apache-675bc649f5-24w6p" I0101 05:01:45.116118 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulDelete" message="Deleted pod: php-apache-675bc649f5-x9nn9" I0101 05:01:45.116123 1 event.go:307] "Event occurred" object="default/php-apache-675bc649f5" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulDelete" message="Deleted pod: php-apache-675bc649f5-d2h2t" I0101 05:01:45.135533 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="32.390299ms" I0101 05:01:45.144045 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="8.463238ms" I0101 05:01:45.144182 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="78.753µs" I0101 05:01:45.350809 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="53.26µs" I0101 05:01:45.372895 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="35.269µs" I0101 05:01:45.394556 1 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="default/php-apache-675bc649f5" duration="49.948µs"
在回收资源的过程是比较慢的,避免回收之后流量突然峰值将服务打满,会缓慢的回收资源
资源限制-名称空间 计算资源配额 computeResourceQuota.yaml
1 2 3 4 5 6 7 8 9 10 11 12 apiVersion: v1 kind: ResourceQuota metadata: name: compute-resources namespace: test-ns spec: hard: pods: "20" requests.cpu: "20" requests.memory: 100Gi limits.cpu: "40" limits.memory: 200Gi
1 2 3 4 5 6 7 [root@master helm]# kubectl apply -f computeResourceQuota.yaml resourcequota/compute-resources created [root@master helm]# kubectl get quota -A NAMESPACE NAME AGE REQUEST LIMIT test-ns compute-resources 61s pods: 0/20, requests.cpu: 0/20, requests.memory: 0/100Gi limits.cpu: 0/40, limits.memory: 0/200Gi [root@master helm]#
配置对象数量配额限制 objResourceQuota.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 apiVersion: v1 kind: ResourceQuota metadata: name: object-counts namespace: test-ns spec: hard: configmaps: "10" persistentvolumeclaims: "4" replicationcontrollers: "20" secrets: "10" services: "10" services.loadbalancers: "2"
1 2 3 4 5 6 7 8 [root@master helm]# kubectl apply -f objResourceQuota.yaml resourcequota/object-counts created [root@master helm]# kubectl get quota -A NAMESPACE NAME AGE REQUEST LIMIT test-ns compute-resources 4m12s pods: 0/20, requests.cpu: 0/20, requests.memory: 0/100Gi limits.cpu: 0/40, limits.memory: 0/200Gi test-ns object-counts 3s configmaps: 1/10, persistentvolumeclaims: 0/4, replicationcontrollers: 0/20, secrets: 0/10, services: 0/10, services.loadbalancers: 0/2 [root@master helm]#
配置 CPU 和 内存 LimitRange containerQuota.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 apiVersion: v1 kind: LimitRange metadata: name: mem-limit-range spec: limits: - default: memory: 50Gi cpu: 5 defaultRequest: memory: 1Gi cpu: 1 type: Container
1 2 3 4 [root@master helm]# kubectl get limits -o wide NAME CREATED AT mem-limit-range 2025-01-01T05:17:28Z [root@master helm]#
字面意思: 对 Container 的cpu / mem 的限制
部署ELK平台 命名空间 es-ns.yaml
1 2 3 4 apiVersion: v1 kind: Namespace metadata: name: kube-logging
elasticsearch es.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 apiVersion: v1 kind: Service metadata: name: elasticsearch namespace: kube-logging labels: k8s-app: elasticsearch-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "Elasticsearch" spec: ports: - port: 9200 protocol: TCP targetPort: db selector: k8s-app: elasticsearch-logging --- apiVersion: v1 kind: ServiceAccount metadata: name: elasticsearch-logging namespace: kube-logging labels: k8s-app: elasticsearch-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: elasticsearch-logging labels: k8s-app: elasticsearch-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "services" - "namespaces" - "endpoints" verbs: - "get" --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: namespace: kube-logging name: elasticsearch-logging labels: k8s-app: elasticsearch-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: elasticsearch-logging namespace: kube-logging apiGroup: "" roleRef: kind: ClusterRole name: elasticsearch-logging apiGroup: "" --- apiVersion: apps/v1 kind: StatefulSet metadata: name: elasticsearch-logging namespace: kube-logging labels: k8s-app: elasticsearch-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile srv: srv-elasticsearch spec: serviceName: elasticsearch-logging replicas: 1 selector: matchLabels: k8s-app: elasticsearch-logging template: metadata: labels: k8s-app: elasticsearch-logging kubernetes.io/cluster-service: "true" spec: serviceAccountName: elasticsearch-logging containers: - image: 192.168 .16 .110 :20080/library/elasticsearch:7.9.3 name: elasticsearch-logging resources: limits: cpu: 1000m memory: 2Gi requests: cpu: 100m memory: 500Mi ports: - containerPort: 9200 name: db protocol: TCP - containerPort: 9300 name: transport protocol: TCP volumeMounts: - name: elasticsearch-logging mountPath: /usr/share/elasticsearch/data/ env: - name: "NAMESPACE" valueFrom: fieldRef: fieldPath: metadata.namespace - name: "discovery.type" value: "single-node" - name: ES_JAVA_OPTS value: "-Xms512m -Xmx2g" volumes: - name: elasticsearch-logging hostPath: path: /data/es/ nodeSelector: es: data tolerations: - effect: NoSchedule operator: Exists initContainers: - name: elasticsearch-logging-init image: 192.168 .16 .110 :20080/library/alpine:3.6 command: ["/sbin/sysctl" ,"-w" ,"vm.max_map_count=262144" ] securityContext: privileged: true - name: increase-fd-ulimit image: 192.168 .16 .110 :20080/stady/busybox:1.28.3 imagePullPolicy: IfNotPresent command: ["sh" ,"-c" ,"ulimit -n 65536" ] securityContext: privileged: true - name: elasticsearch-volume-init image: 192.168 .16 .110 :20080/library/alpine:3.6 command: - chmod - -R - "777" - /usr/share/elasticsearch/data/ volumeMounts: - name: elasticsearch-logging mountPath: /usr/share/elasticsearch/data/
logstash logstash.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 apiVersion: v1 kind: Service metadata: name: logstash namespace: kube-logging spec: ports: - port: 5044 targetPort: beats selector: type: logstash clusterIP: None --- apiVersion: apps/v1 kind: Deployment metadata: name: logstash namespace: kube-logging spec: selector: matchLabels: type: logstash template: metadata: labels: type: logstash srv: srv-logstash spec: containers: - image: 192.168 .16 .110 :20080/library/kubeimages/logstash:7.9.3 name: logstash ports: - containerPort: 5044 name: beats command: - logstash - '-f' - '/etc/logstash_c/logstash.conf' env: - name: "XPACK_MONITORING_ELASTICSEARCH_HOSTS" value: "http://elasticsearch:9200" - name: ELASTICSEARCH_HOST value: "elasticsearch" - name: ELASTICSEARCH_PORT value: "9200" volumeMounts: - name: config-volume mountPath: /etc/logstash_c/ - name: config-yml-volume mountPath: /etc/share/logstash/config/ - name: timezone mountPath: /etc/localtime resources: limits: cpu: 1000m memory: 2048Mi requests: cpu: 512m memory: 512Mi volumes: - name: config-volume configMap: name: logstash-conf items: - key: logstash.conf path: logstash.conf - name: timezone hostPath: path: /etc/localtime - name: config-yml-volume configMap: name: logstash-yml items: - key: logstash.yml path: logstash.yml --- apiVersion: v1 kind: ConfigMap metadata: name: logstash-conf namespace: kube-logging labels: type: logstash data: logstash.conf: |- input { beats{ port => 5044 } } filter{ # 处理ingress 日志 if [kubernetes][container][name] == "ingress-nginx-controller" { json { source => "message" target => "ingress_log" } if [ingress_log][requesttime]{ mutate{ convert => ["[ingress_log][requesttime]","float"] } } if [ingress_log ][upstremtime ]{ mutate { convert => ["[ingress_log][upstremtime]" ,"float" ] } } if [ingress_log ][status ]{ mutate { convert => ["[ingress_log][status]" ,"float" ] } } if [ingress_log ][httphost ] and [ingress_log ][uri ] { mutate { add_field => { "[ingress_log][entry]" => "%{[ingress_log][httphost]} %{[ingress_log][uri]} " } } mutate { split => ["[ingress_log][entry]" ,"/" ] } if [ingress_log ][entry ][1 ]{ mutate { add_field => {"[ingress_log][entrypoint]" => "%{[ingress_log][entry][0]} /%{[ingress_log][entry][1]} " } remove_field => "[ingress_log][entry]" } } } } mutate{ rename => ["kubernetes" ,"k8s" ] remove_field => "beat" remove_field => "tmp" remove_field => "[k8s][labels][app]" } } output { elasticsearch { hosts => ["http://elasticsearch:9200" ] codec => json index => "logstash-%{+YYYY.MM.DD} " } stdout { codec => rubydebug } } --- apiVersion: v1 kind: ConfigMap metadata: name: logstash-yml namespace: kube-logging labels: type: logstash data: logstash.yml: |- http.host: "0.0.0.0" elasticsearch_host: "elasticsearch" elasticsearch_port: 9200 xpack.monitoring.elasticsearch.hosts: "http://elasticsearch:9200"
filebeat filebeat.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 apiVersion: v1 kind: ConfigMap metadata: name: filebeat-config namespace: kube-logging labels: k8s-app: filebeat data: filebeat.yml: |- filebeat.inputs: - type: container enable: true paths: - /var/log/containers/*log processors: - add_kubernetes_metadata: host: ${NODE_NAME} matchers: - logs_path: logs_path: "/var/log/containers/" output.logstash: hosts: ["logstash:5044"] enable: true --- apiVersion: v1 kind: ServiceAccount metadata: name: filebeat namespace: kube-logging labels: k8s-app: filebeat --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: filebeat labels: k8s-app: filebeat rules: - apiGroups: ["" ] resources: - namespaces - pods verbs: ["get" ,"watch" ,"list" ] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: filebeat subjects: - kind: ServiceAccount name: filebeat namespace: kube-logging roleRef: kind: ClusterRole name: filebeat apiGroup: rbac.authorization.k8s.io --- apiVersion: apps/v1 kind: DaemonSet metadata: name: filebeat namespace: kube-logging labels: k8s-app: filebeat spec: selector: matchLabels: k8s-app: filebeat template: metadata: labels: k8s-app: filebeat spec: serviceAccountName: filebeat terminationGracePeriodSeconds: 30 containers: - name: filebeat image: 192.168 .16 .110 :20080/library/kubeimages/filebeat:7.9.3 args: [ "-c" ,"/etc/filebeat.yml" ,"-e" ,"-httpprof" ,"0.0.0.0:6060" ] env: - name: NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName - name: ELASTICSEARCH_HOST value: elasticsearch-logging - name: ELASTICSEARCH_PORT value: "9200" securityContext: runAsUser: 0 resources: limits: memory: 1000Mi cpu: 1000m requests: memory: 100Mi cpu: 100m volumeMounts: - name: config mountPath: /etc/filebeat.yml readOnly: true subPath: filebeat.yml - name: data mountPath: /usr/share/filebeat/data - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: varlogcontainers mountPath: /var/log/containers readOnly: true - name: varlogpods mountPath: /var/log/pods readOnly: true - name: timezone mountPath: /etc/localtime volumes: - name: config configMap: defaultMode: 0600 name: filebeat-config - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: varlogcontainers hostPath: path: /var/log/containers - name: varlogpods hostPath: path: /var/log/pods - name: inputs configMap: defaultMode: 0600 name: filebeat-inputs - name: data hostPath: path: /data/filebeat-data type: DirectoryOrCreate - name: timezone hostPath: path: /etc/localtime tolerations: - effect: NoExecute key: dedicated operator: Equal value: gpu - effect: NoSchedule operator: Exists
kibana kibana.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 apiVersion: v1 kind: ConfigMap metadata: namespace: kube-logging name: kibana-config labels: k8s-app: kibana data: kibana.yml: |- server.name: kibana server.host: "0" i18n.locale: zh-CN elasticsearch: hosts: ${ELASTICSEARCH_HOSTS} --- apiVersion: v1 kind: Service metadata: name: kibana namespace: kube-logging labels: k8s-app: kibana kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "Kibana" ser: ser-kibana spec: type: NodePort ports: - port: 5601 protocol: TCP targetPort: ui selector: k8s-app: kibana --- apiVersion: apps/v1 kind: Deployment metadata: name: kibana namespace: kube-logging labels: k8s-app: kibana kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile srv: srv-kibana spec: replicas: 1 selector: matchLabels: k8s-app: kibana template: metadata: labels: k8s-app: kibana spec: containers: - name: kibana image: 192.168 .16 .110 :20080/library/kubeimages/kibana:7.9.3 resources: limits: cpu: 1000m memory: 1024Mi requests: cpu: 100m memory: 100Mi env: - name: ELASTICSEARCH_HOSTS value: http://elasticsearch:9200 ports: - containerPort: 5601 name: ui protocol: TCP volumeMounts: - name: config mountPath: /usr/share/kubana/config/kibana.yml readOnly: true subPath: kibana.yml volumes: - name: config configMap: name: kibana-config --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: kibana namespace: kube-logging spec: ingressClassName: nginx rules: - host: kibana.my-test-ingress.com http: paths: - path: / pathType: Prefix backend: service: name: kibana port: number: 5601
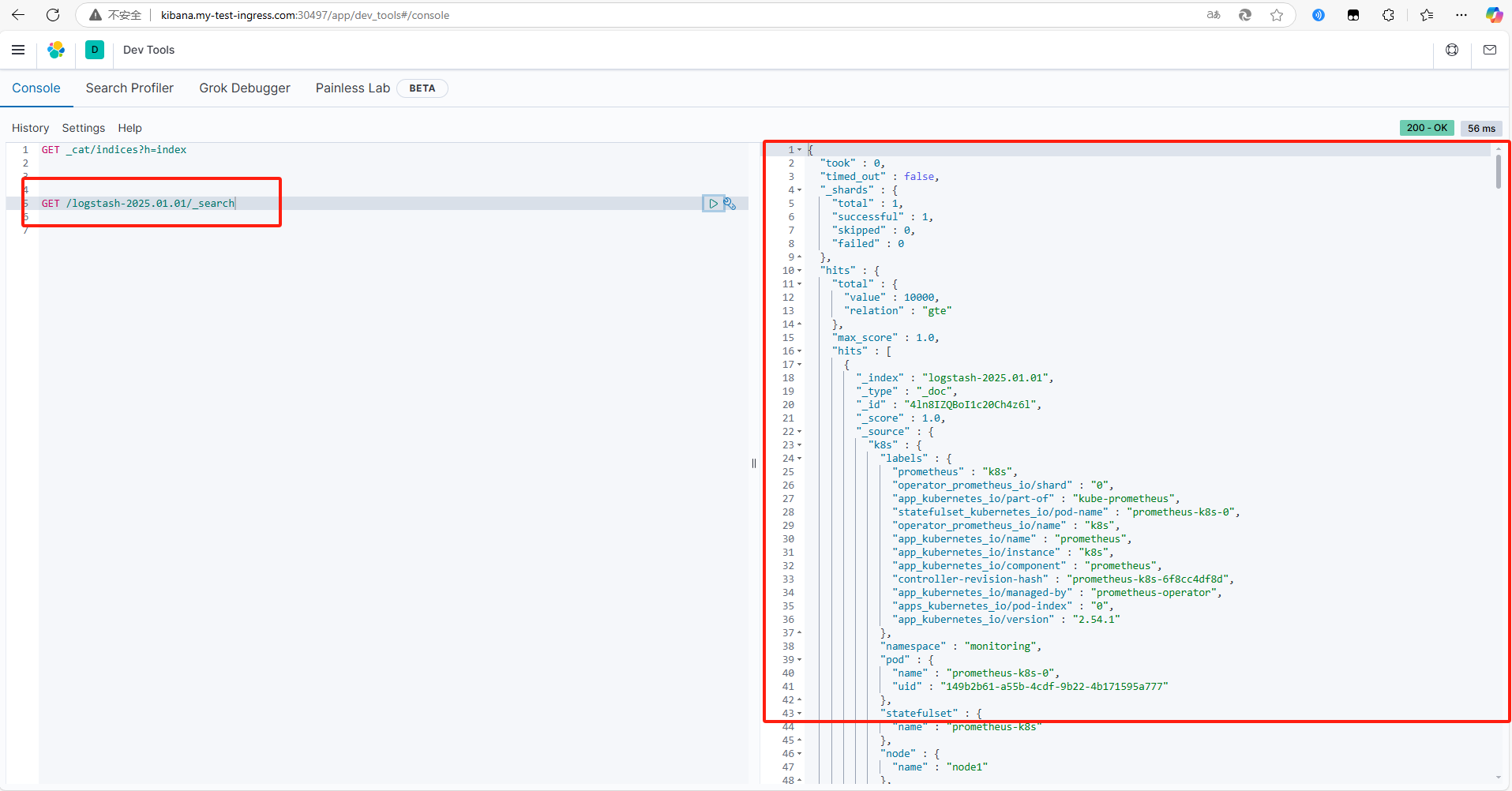
至此 整个ELK集群搭建完毕 可以正常的查询到日志
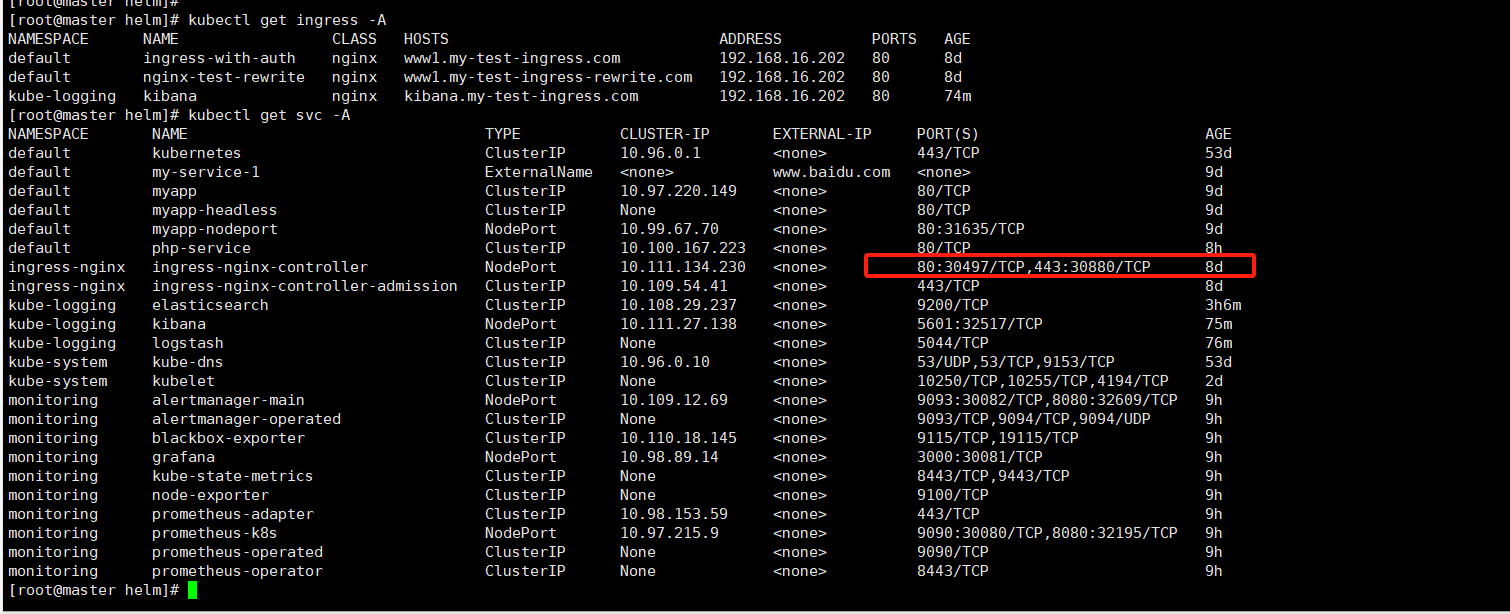
验证 查看 ingress 登录端口, 并配置好域名解析
登录到kibana 查询
因为虚拟机资源较少 该服务验证完旧结束了